La Saison 12 de la BattleDev s’est tenue le 6 Novembre 2018, et plus de 3000 développeurs s’y sont affrontés. Les candidats devaient choisir parmi 8 langages de programmation au total (C, C++, C#, Java, PHP, Ruby, Python, JS).
Les soumissions de certains candidats sont publiées par Isograd en guise de solutions, mais ce sont souvent des codes écrits dans l’urgence, pas toujours corrects et surtout sans aucune explication, puisqu’ils ont été écrits pendant le concours en temps limité, et non pour être lus. C’est un peu dommage, car les problèmes sont souvent très intéressants et méritent d’être explorés en détail, mais ce format ne permet pas aux participants d’apprendre à les résoudre.
Ce post a pour but de revenir tranquillement sur les problèmes proposés pendant la saison 12, pour donner quelques explications supplémentaires et en apprendre un peu plus sur les algorithmes qu’il fallait déployer pour finir dans les temps. Le challenge 5 était de loin le plus difficile, mais en le décomposant il reste tout à fait raisonnable. Trois solutions qui valent le détour sont également détaillées pour la résolution du challenge 6.
Les implémentations seront proposées en Ruby, parce que c’est un langage qui est très adapté au format du concours, et trop souvent sous-estimé, plus élégant et efficace que Python ou Javascript sans être aussi difficile à lire que C ou PHP. Il permet notamment de résoudre 5 challenges sur 6 en moins de 50 lignes de code au total sans rien sacrifier en lisibilité. Mais ce choix n’a absolument aucune importance, ce sont les algorithmes qui sont importants, plus que leur implémentation, et il est très facile de transposer ces solutions dans d’autres langages.
Index
- Challenge 1 : Vente aux enchères
- Challenge 2 : Mots magiques
- Challenge 3 : Fonction mystérieuse
- Challenge 4 : Professeur populaire
- Challenge 5 : Professeur débordé
- Challenge 6 : Fonction mystérieuse (bis)
Challenge 1
Énoncé
Finalement, pour créer sa société, il n’est pas nécessaire d’avoir une idée. On peut prendre une idée qui marche déjà et refaire la même chose. Ensuite, il suffit d’acheter des clics et d’avoir un e-marketing performant. Vous voyez donc les choses en grand : vous allez clôner ebay car faire un site d’enchères ce n’est pas bien compliqué. On reçoit des enchères, on vérifie qu’elles sont strictement supérieures au prix de réserve et on détermine le nom du gagnant à la fin.
Entrée
- Ligne 1 : un entier N compris entre 2 et 1 000 correspondant au nombre d’enchères reçues.
- Ligne 2 : un entier compris entre 1 et 500 correspondant au prix de réserve de l’objet.
- Lignes 3 à N+2 : un entier P compris entre 1 et 10 000 et une chaîne de caractères E séparés par un espace où P correspond au prix de l’enchère et E correspond au prénom de l’enchérisseur.
Sortie
Une chaîne de caractères correspondant au prénom du vainqueur. Si personne ne remporte l’enchère (car toutes les offres sont inférieures ou égales au prix de réserve), renvoyez KO.
Solution
Rien de particulièrement intéressant ici, il suffit de parcourir la liste des enchères et de retourner le prénom de celui qui a placé la plus haute.
n = $stdin.gets.to_i
price = $stdin.gets.to_i
winner = "KO"
n.times do
bid, name = $stdin.gets.split
if bid.to_i > price
price, winner = bid.to_i, name
end
end
puts winnerOn peut même l’écrire de façon encore plus courte en utilisant la fonction Ruby Array.max_by:
n, price = 2.times.map { $stdin.gets.to_i }
all_bets = n.times.map { $stdin.gets.split } + [[price, "KO"]]
puts all_bets.reverse.max_by { |bet, name| bet.to_i }.lastOn note que max_by renvoie le dernier élément qui atteint le maximum, alors que l’enchère n’est gagnée que lorsque le prix proposé est strictement supérieur au prix précédent. On doit ici renvoyer le premier élément qui atteint le maximum, d’où l’utilisation de Array.reverse.
Challenge 2
Énoncé
Un de vos amis joue dans une équipe de Rugby. Il est lanceur lors des touches. Lors d’une touche le lanceur doit communiquer aux autres joueurs à quelle hauteur il va envoyer le ballon à l’aide d’un code que les adversaires ne doivent pas pouvoir décoder. Pour chaque hauteur, il y a plusieurs codes. Le lanceur crie alors plusieurs mots dont un seul correspond à un code et toute l’équipe peut ainsi déterminer la hauteur choisie.
Votre ami vous présente une liste de mots que les joueurs ont proposé (un mot peut donc figurer plusieurs fois dans sa liste) et vous demande de trouver une méthode pour en extraire des mots “magiques” qui seront utilisés comme code. Il leur associera des hauteurs ensuite. Vous avez décidé qu’un mot magique aurait les caractéristiques suivantes :
- Il doit contenir entre 5 et 7 lettres.
- Il doit commencer par deux lettres de l’alphabet qui se suivent dans l’ordre alphabétique.
- Il doit se terminer par une voyelle (a, e, i, o, u, ou y).
Vous devez déterminer combien de mots magiques différents figurent dans sa liste.
Entrée
- Ligne 1 : un entier N compris entre 10 et 1000 correspondant au nombre de mots dans la liste.
- Ligne 2 à N+1 : une chaîne de caractères contenant entre 2 et 20 caractères en minuscule correspondant à un mot.
Sortie
Un entier correspondant au nombre de mots magiques différents dans la liste.
Solution
Ici non plus, rien de compliqué, il suffit de compter les mots qui conviennent
def valid?(word)
word.size <= 7 && word.size >= 5 &&
"aeiouy".include?(word[-1]) &&
word[0].ord == word[1].ord - 1
end
n = $stdin.gets.to_i
puts n.times.map { $stdin.gets.strip }
.select { |w| valid? w }.uniq.sizeChallenge 3
Énoncé
Depuis les diverses révélations au sujet de la NSA, vous ne faites plus confiance au générateur de nombres aléatoires de votre système d’exploitation. Vous avez donc mis en place la contre-mesure suivante : après avoir tiré un entier aléatoire, vous le passez à une fonction (déterministe) mystérieuse faite maison, qui associe à chaque entier entre 0 et N un autre entier entre 0 et N.
Votre hiérarchie a été tellement séduite par la simplicité de cette idée qu’elle vous a demandé d’étendre cette fonction mystérieuse à des nombres décimaux. Pour cela, vous faites une interpolation linéaire sur chaque intervalle [i, i+1] (cf. exemple ci-dessous pour une explication).
Toutefois, vous commencez à douter : les nombres proches du milieu de l’intervalle [0,N] n’apparaîtraient-ils pas plus souvent que ceux aux extrémités ? Ce serait un défaut fâcheux pour votre génération aléatoire. C’est pourquoi vous voulez déterminer le nombre de fois où la fonction passe par N/2.
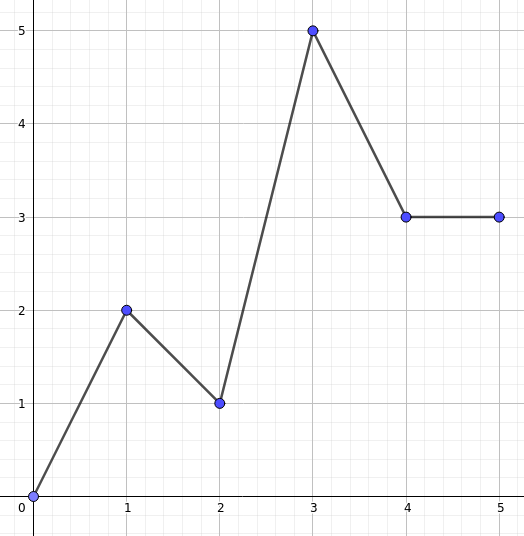
Le graphe ci-dessus représente la fonction interpolée à partir des valeurs :
f(0) = 0, f(1) = 2, f(2) = 1, f(3) = 5, f(4) = 3, f(5) = 3
On constate par exemple qu’entre 2 et 3, f prend toutes les valeurs de 1 à 5, chacune une fois. Donc, comme 1 < 2,5 < 5, il y a un x entre 2 et 3 tel que f(x) = 2,5. On voit aussi que la fonction prend la valeur 1,5 trois fois :
- entre 0 et 1 puisque f(0) < 1,5 < f(1)
- entre 1 et 2 puisque f(1) > 1,5 > f(2)
- puis entre 2 et 3 puisque f(2) < 1,5 < f(3)
De plus, elle prend la valeur 2 deux fois (une fois exactement en 1, puisque f(1) = 2, et une autre fois en un certain point compris entre 2 et 3, puisque f(2) < 2 < f(3)), et la valeur 3 une infinité de fois (en effet, toute entrée entre 4 et 5 donnera une sortie égale à 3, et il y a une infinité de nombres réels compris entre 4 et 5.).
Entrée
- Ligne 1: un entier N entre 1 et 99.
- Ligne 2 : N+1 entiers (et non N, attention !) séparés par des espaces, indiquant f(0), f(1), …, f(N) (f étant votre fonction), tous sont compris entre 0 et N inclus.
Sortie
Un entier, le nombre d’entrées x différentes comprises entre 0 et N pour lesquelles f(x) vaut N/2. Si ce nombre est infini, écrivez INF sur la sortie.
Exemple
L’entrée correspondant à l’exemple donné plus haut est la suivante :
5
0 2 1 5 3 3La sortie attendue est 1, en effet il y a exactement un x pour lequel f(x) = 5/2 = 2,5, comme dit plus haut ce x est compris entre 2 et 3.
Sur l’entrée suivante :
4
0 2 2 1 0La sortie attendue est INF.
Solution
Derrière cet énoncé un peu cryptique et noyé dans un contexte pas vraiment nécessaire, il y a en fait une question assez simple: Combien de fois une fonction affine par morceaux1 atteint-elle N/2 ?
Pour y répondre, il suffit d’utiliser le théorème des valeurs intermédiaires2. Le nom est un peu pompeux, mais le résultat est très simple. La fonction atteint la valeur y quand f(i) = y, ou f(i) < y < f(i+1), ou bien encore f(i) > y > f(i+1).
Il y a tout de même un cas particulier: si f(i) = y et f(i+1) = y, alors f vaut y sur tout l’intervalle [i, i+1], donc une infinité de fois.
Il suffit alors de parcourir le tableau des valeurs qui nous est fourni, et de compter combien de fois la valeur N / 2 est atteinte.
n = $stdin.gets.to_i
f_vals = $stdin.gets.strip.split.map(&:to_i)
def count(f, n, m)
if n.times.any? { |i| f[i] == m && f[i+1] == m }
return "INF"
else
f.count { |v| v == m }.+
n.times.count { |i| f[i] < m && f[i+1] > m } +
n.times.count { |i| f[i] > m && f[i+1] < m }
end
end
puts count(f_vals, n, n / 2)Challenge 4
Énoncé
Vous vous êtes enfin décidé à monétiser vos connaissances en algorithmique en proposant des cours particuliers à des parents remplis d’espoirs injustifiés. Vous devenez rapidement très populaire, trop populaire, vous n’êtes plus sûr de pouvoir assurer tous vos cours. Pour avoir plus de chance d’acquérir votre savoir, tous vos élèves vous proposent deux créneaux de 60 minutes pendant lesquels ils sont disponibles, vous ne pourrez leur donner cours que sur un seul de ces deux créneaux (si vous avez le temps).
Sachant que vous ne pouvez donner cours qu’à un seul élève en même temps et que vous ne pouvez pas commencer un cours et en terminer un autre à la même minute, combien d’élèves différents pouvez-vous prendre au maximum ?
Indication : vous pouvez procéder par énumération exhaustive (force brute).
Entrée
- Ligne 1 : un entier N entre 3 et 8 inclus, le nombre d’étudiants.
- Lignes 2 à N+1 : deux entiers entre 0 et 1000 inclus, les deux débuts de créneaux (en minutes) auxquels un étudiant est disponible, chaque créneau a une durée de 60 minutes à partir des débuts indiqués.
Sortie
Le nombre maximum d’étudiant différents qu’il est possible de prendre.
Solution
L’indication est claire: on peut procéder par force brute, alors inutile de se priver.
Le tout est de le faire de façon succinte. Pour cela, on va générer toutes les possibilités de planning, les trier par nombre d’étudiants décroissant, et les tester une par une. Pour générer toutes ces possibilités, on peut encoder les plannings de la façon suivante: pour chaque étudiant, choisir le créneau 0, le créneau 1, ou bien ne pas choisir l’étudiant, qui sera encodé par 2. Chaque planning correspond alors à une suite de n chiffres entre 0 et 2, c’est à dire un entier de 0 à 3n-1 écrit en base 3. On peut convertir un nombre en base 3 en un planning sous forme de liste d’entiers en Ruby avec
number_in_base_3 = number.to_s(3)
planning = number_in_base_3.chars.map(&:to_i)On peut alors générer facilement tous les plannings et les trier. Il suffit ensuite de trouver le premier qui est un planning valide (pas deux étudiants la même heure) dans la liste.
n = $stdin.gets.to_i
time = n.times.map { $stdin.gets.split.map(&:to_i) }
def valid?(choice, time)
h = choice.map.with_index { |c, i| time[i][c] }.compact.sort
(h.size-1).times.all? { |i| h[i] + 60 < h[i+1] }
end
choices = (3**n).times.map do
|i| i.to_s(3).ljust(n, '0').chars.map(&:to_i)
end.sort_by { |x| x.count { |i| i == 2 } }
puts choices.find { |c| valid? c, time }.count { |i| i != 2 }Challenge 5
Énoncé
Vos élèves sont énervés, ils vous accusent d’annuler des cours en permanence et vous accablent de mauvais commentaires sur internet. Vous allez devoir arrêter d’accepter des étudiants si vous ne pouvez pas donner cours à chacun d’entre eux individuellement. Comme pour l’exercice précédent, tous les étudiants vous donnent deux créneaux de 60 minutes et vous devez leur donner cours sur l’un des deux créneaux. Cette fois-ci, tout ce qui vous intéresse c’est de savoir s’il vous est possible de donner cours à tout le monde et le cas échéant sur quels créneaux.
Attention : le nombre d’étudiants est beaucoup plus grand que dans l’exercice précédent, votre solution doit s’exécuter en temps polynomial.
Entrée
- Ligne 1 : un entier N entre 3 et 1000 inclus, le nombre d’étudiants.
- Lignes 2 à N+1 : deux entiers entre 0 et 300.000, les deux débuts de créneaux (en minutes) auxquels un étudiant est disponible, chaque créneau a une durée de 60 minutes à partir des débuts indiqués (vos journées sont très longues).
Sortie
Vous afficherez simplement KO s’il est impossible de donner cours à tout le monde. S’il est possible de donner cours à tout le monde, vous indiquerez, pour chaque étudiant, sur quel créneau vous lui donnerez cours 1 ou 2 dans le même ordre qu’en entrée (on acceptera toutes les solutions possibles). Vous pouvez séparer les étudiant par des sauts de lignes.
Solution
Celui-ci est à mon avis le plus difficile des exercices proposés, mais en le décomposant en petites étapes il reste tout à fait faisable.
Nous allons donc d’abord ramener le problème à 2-SAT, que l’on peut résoudre facilement en calculant les composantes fortement connexes d’un graphe, ce que nous ferons avec l’algorithme de Tarjan. Tout cela sera possible en temps polynomial3.
Cette méthode de résolution de 2-SAT a été proposée par B. Aspvall, M. F. Plass, et R. E. Tarjan en 1979. [Lire l’article en ligne]
Étape 1: Transformation vers 2-SAT
Le problème 2-SAT4 est celui de la satisfiabilité d’une formule booléenne sous forme normale conjonctive avec 2 littéraux par clause. Autrement dit, on a une formule
(x1 ∨ x2) ∧ (¬ x1 ∨ x3) ∧ (x2 ∨ x3) ∧ (x4 ∨ ¬ x1)
avec xi qui peut être “vrai” ou “faux”, et on souhaite savoir si la formule est satisfiable, i.e. s’il existe un moyen d’assigner “vrai” ou “faux” à chaque xi pour que la formule s’évalue à “vrai”.
“¬”, “∧”, et “∨” correspondent respectivement à la négation, “et” et “ou”.
Pour commencer, on note xi la variable qui indique si on utilise le premier créneau pour l’élève i. Si xi est “vrai”, on fait donc cours à l’élève i pendant le créneau 1, et sinon, c’est à dire si ¬xi est “vrai”, alors ce sera pendant le créneau 2.
On va maintenant construire avec ces variables une formule qui est satisfiable si et seulement si on peut faire cours à tout le monde. Il suffit pour cela d’encoder les collisons entre les différents créneaux. S’il y a une collision entre le créneau i1 et le créneau j1, alors il suffit de ne pas choisir au moins l’un des deux pour qu’il n’y ait pas de problème. On ajoute donc (¬xi ∨ ¬xj) à notre formule. S’il y a une collision entre les créneaux i1 et j2, il faut donc ajouter (¬xi ∨ ¬¬xj), c’est à dire (¬xi ∨ xj), etc.
Étape 2: Graphe d’implications
On peut convertir la formule 2-SAT en un graphe d’implications. En effet l’expression (a ∨ b) est équivalente à (¬a ⇒ b ∧ ¬b ⇒ a), ce qui permet de voir toute la formule comme une liste d’implications.
Pour chaque variable x, on crée dans le graphe un noeud vx et un noeud v¬ x. On ajoute ensuite une arrête de a à b pour chaque implication (a ⇒ b).
Dans ce graphe, s’il y a un chemin de a à b, alors a ⇒ b. Il suffit maintenant de choisir une assignation des variables pour que le graphe de contienne pas (vrai ⇒ faux). On peut voir assez facilement que si on a (x → ¬ x), alors x ne peut pas être “vrai”. Inversement, si (¬ x → x), alors x ne peut pas être “faux” car on aurait (vrai → faux). Enfin, si on a (x → ¬ x) et (¬ x → x), alors il n’y a pas de solution: x ne peut être ni “vrai” ni “faux”.
Étape 3: Composantes fortement connexes
On va maintenant décomposer ce graphe en composantes fortement connexes. Deux noeuds d’un graphe sont dans la même composante fortement connexe si chacun est accessible depuis l’autre.
Par exemple, les composantes fortement connexes de ce graphe figurent en jaune:

On peut trouver les composantes fortement connexes d’un graphe en temps linéaire avec l’algorithme de Tarjan
Étape 4: Résolution de 2-SAT
Si x et ¬x sont dans la même composante connexe, alors il est impossible de faire cours à tout le monde. On peut montrer aussi que si aucun (x, ¬x) ne sont dans la même composante connexe, alors on peut faire cours à tout le monde5.
On a même un résultat un peu meilleur: si la formule est satisfiable, on toujours peut trouver une évaluation des variables qui satisfait la formule à partir de la décomposition en composantes fortement connexes.
L’algorithme de Tarjan donne les composantes fortement connexes dans un ordre bien particulier: un ordre topologique. Si a est dans une composante obtenue après celle de b, alors il n’y a pas de chemin de a à b, mais il peut y en avoir un de b à a. Or on sait que si on a (x → ¬x), alors x ne peut pas être “vrai”. On assigne donc “faux” à celui des deux qui a été obtenu en premier dans la décomposition.
Résultat final
def strongly_connected_components(graph) # Tarjan
components = []
dfs_num = []
dfs_time = 0
wait_stack = []
is_waiting = [ false ] * graph.size
dfs = lambda do |v|
wait_stack << v
is_waiting[v] = true
dfs_num[v] = dfs_time
dfs_time += 1
dfs_min = dfs_num[v]
graph[v].each do |w|
if dfs_num[w].nil?
dfs_min = [ dfs_min, dfs.call(w) ].min
elsif is_waiting[w] && dfs_min > dfs_num[w]
dfs_min = dfs_num[w]
end
end
if dfs_min == dfs_num[v]
u = -1
components << []
while u != v
u = wait_stack.pop
is_waiting[u] = false
components[-1] << u
end
end
dfs_min
end
graph.size.times { |v| dfs.call(v) if dfs_num[v].nil? }
scc = []
components.reverse
.each_with_index { |c, i| c.each { |v| scc[v] = i } }
scc
end
def _v(i) # integer encoding [-n, n] -> [0, 2n]
i > 0 ? 2 * i - 2 : - 2 * i - 1
end
def two_sat(n, formula)
graph = Array.new(2*n) { Array.new }
formula.each do |x,y|
graph[_v -x] << _v(y)
graph[_v -y] << _v(x)
end
scc = strongly_connected_components(graph)
return nil if (1..n).any? { |i| scc[_v i] == scc[_v -i] }
(1..n).map { |i| scc[_v -i] < scc[_v i] }
end
def intersect?(students, v1, c1, v2, c2)
(students[v1 - 1][c1] - students[v2 - 1][c2]).abs <= 60
end
n = $stdin.gets.to_i
students = n.times.map { $stdin.gets.split.map(&:to_i) }
formula = []
(1..n).each do |v1|
(1...v1).each do |v2|
[0,1].product([0,1]).each do |c1, c2|
if intersect?(students, v1, c1, v2, c2)
formula << [ c1 == 0 ? -v1 : v1, c2 == 0 ? -v2 : v2 ]
end
end
end
end
res = two_sat n, formula
if res.nil?
puts "KO"
else
puts (0...n).map { |i| res[i] ? 1 : 2 }
endC’est long et difficile à lire, je sais. Mais c’est correct, et efficace.
Si on a pas sous la main une implémentation de l’algorithme de Tarjan (ça peut arriver à tout le monde), on peut appliquer une méthode un peu plus rustique, mais aussi plus courte à écrire.
Pour cela, rappelons les points clés:
- si on a (xi → ¬xi) et (¬xi → xi) alors il n’y a pas de solutions
- si on a (xi → ¬xi) alors xi est “faux”
- si on a (¬xi → xi) alors xi est “vrai”
- il faut propager les implications: si (a → b) et a est “vrai”, alors b est “vrai”
On peut facilement obtenir la liste des variables qui doivent être vraies ou fausses avec un parcours en profondeur du graphe d’implications. Il suffit donc de vérifier d’abord s’il y a des solutions, et si c’est le cas, de choisir une valeur pour chaque variable, en propageant ce choix à chaque fois. On note que pour propager le choix après avoir choisi a, il suffit de propager ce choix aux b tels que (a → b), c’est à dire exactement les noeuds énumérés par un parcours de profondeur à partir de a. On pourrait au moment de propager ces valeurs revenir sur un choix précédent, mais ça n’a aucune importance car les quatre propriétés citées ci-dessus resteront vérifiées, donc la solution sera quand même correcte.
def dfs(graph, node)
visited, queue = [], [node]
while (curr = queue.pop)
next if visited.include? curr
visited << curr
queue += graph[curr]
end
visited
end
n = $stdin.gets.to_i
students = n.times.map { $stdin.gets.split.map(&:to_i) }
graph = Array.new(2*n) { Array.new }
(0...n).each do |v1|
(0...v1).each do |v2|
[0,1].product([0,1]).each do |c1, c2|
if (students[v1][c1] - students[v2][c2]).abs <= 60
graph[ v1 + n * c1 ] << (v2 + n * (1 - c2))
graph[ v2 + n * c2 ] << (v1 + n * (1 - c1))
end
end
end
end
true_var = Array.new(n) { |i| dfs(graph, i).include?(i+n) }
false_var = Array.new(n) { |i| dfs(graph, i+n).include? i }
if (0...n).any? { |i| true_var[i] && false_var[i] }
puts "KO"
else
res = Array.new(n)
n.times do |i|
next unless res[i].nil?
cur = true_var[i] ? i : i + n
dfs(graph, cur).each { |j| res[j%n] = (j<n) ? 1 : 2 }
end
puts res
endNote: l’encodage est ici un peu différent, avec (x + n) pour représenter ¬x. Comme on ne construit pas explicitement la formule, inutile de s’embêter avec l’encodage précédent.
Cette implémentation s’exécute en temps quadratique, contre linéaire pour la version qui utilisait l’algorithme de Tarjan, mais le concours demande seulement une version polynomiale, donc quadratique reste acceptable.
Challenge 6
Énoncé
Souvenez-vous, dans l’un des problèmes précédents, vous disposiez d’une fonction mystérieuse obtenue par interpolation linéaire, et vous vouliez savoir combien de fois elle atteignait la valeur N/2. Maintenant, vous appliquez la fonction plusieurs fois, ce qui, vous l’espérez, améliorera l’efficacité de votre contre-mesure cryptographique en mélangeant mieux l’intervalle [0,N]. La question est alors : combien de fois est-ce que la fonction itérée passe-t-elle par la valeur N/2. Pour éviter de nombreux cas particuliers, on va se limiter à des valeurs de N impaires.
Entrée
- Ligne 1 : un entier impair N entre 1 et 99.
- Ligne 2 : N+1 entiers (et non N, attention !) séparés par des espaces, indiquant f(0), f(1), …, f(N) (f étant votre fonction).
- Ligne 3 : un entier k entre 1 et 1000, le nombre d’itérations.
Sortie
Les trois derniers chiffres (en base 10) du nombre d’entrées différentes comprises entre 0 et N pour lesquelles f itérée k fois vaut N/2.
La raison pour laquelle on vous demande seulement les 3 derniers chiffres est que quand le nombre d’itérations k est grand, le nombre de points sur lesquels la fonction itérée vaut N/2 peut devenir très grand.
Exemple
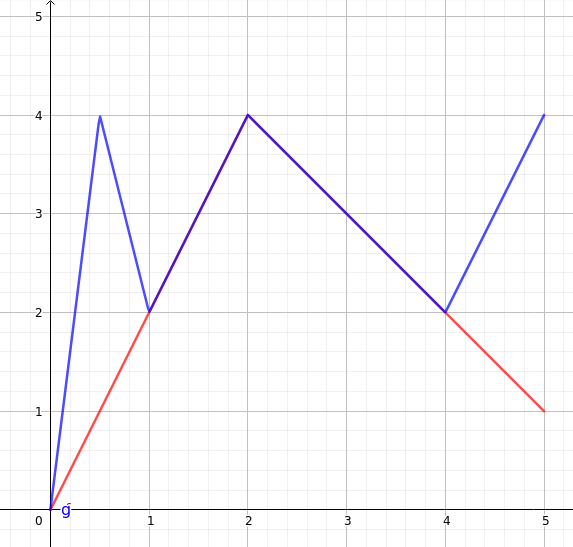
Pour N=5, considérons la fonction qui vaut :
f(0) = 0, f(1) = 2, f(2) = 4, f(3) = 3, f(4) = 2, f(5) = 1
f elle-même atteint 2,5 deux fois, mais la fonction qui renvoie f(f(f(x))) sur l’entrée x, elle, atteint 2,5 cinq fois. Dans la figure ci-dessous, on a représenté f en rouge et f itérée trois fois en bleu.
Donc, sur l’entrée suivante :
5
0 2 4 3 2 1
1votre code devra renvoyer 2, tandis que sur la suivante :
5
0 2 4 3 2 1
3il devra renvoyer 5.
Solution 1 : Mémoïsation
La clé ici est de remarquer que fk+1 passe par m entre i et i+1 autant de fois que fk passe par m entre f(i) et f(i+1). On peut alors calculer le résultat récursivement, en mémoïsant les résultats intermédiaires pour éviter de les calculer plusieurs fois inutilement. On construit pour cela un tableau C tel que C[k, i, j] représente le nombre de passages de la fonction fk par m entre les abscisses i et j. Pour k = 0, on a déjà résolu la question dans le challenge 3, et sinon il suffit d’utiliser la relation de récurrence énoncée plus haut. Si on a déjà calculé avant le nombre d’intersections pour un triplet (k, i, j), on renvoie directement la valeur de C[k, i, j], et sinon on calcule ce nombre, sans oublier de le stocker dans le tableau pour éviter de le recalculer la prochaine fois, d’où le nom de mémoïsation.
n = $stdin.gets.to_i
f = $stdin.gets.strip.split.map(&:to_i)
k = $stdin.gets.to_i
class Memoizer
def initialize(n, f, k)
@n, @f, @k, @m = n, f, k, n / 2.0
# @count[k][i][j] : nb de passage de f^k par m entre i et j
@count = Array.new(k){ Array.new(n+1){ Array.new(n+1) } }
end
def compute(k, i, j)
if k == 0
(i < m && m < j) || (i > m && m > j) ? 1 : 0
elsif i > j
compute(k, j, i)
elsif not @count[k][i][j].nil?
@count[k][i][j]
else
@count[k][i][j] = (i...j).map do |u|
compute(k-1, @f[u], @f[u+1])
end.sum % 1000
end
end
end
puts Memoizer.new(n, f, k).compute(k, 0, n)Solution 2 : Exponentiation rapide
On peut également voir ce problème de façon matricielle : le nombre de passages de f par (i + 1/2) entre j et j+1 correspond au coefficient Mi,j d’une matrice de comptage. Cette matrice a une propriété très intéressante : la matrice de comptage de fk est exactement la puissance k-ème de la matrice de comptage de f.
Courte preuve:
fk+1 passe par m entre j et j+1 autant de fois que
fk passe par m entre f(j) et f(j+1)
#{ f^(k+1) passe par (i + 1/2) dans [j, j+1] } =
somme sur u :
#{f^k passe par (i+1/2) dans [u, u+1]}
* #{[u, u+1] est dans [f(j), f(j+1)]}
#{ f^(k+1) passe par (i + 1/2) dans [j, j+1] } =
somme sur u :
#{f^k passe par (i+1/2) dans [u, u+1]}
* #{f passe par u+1/2 dans [j, j+1]}
M^(k+1) [i, j] = somme([ (M^k [i,u]) * M[u,j] pour u < n ])
M^(k+1) = M^k * MIl suffit donc de calculer cette matrice, puis de l’élever à la puissance k. Seulement, un bête produit matriciel ne fonctionne pas ici, car la limite de temps serait dépassée. Il faut donc utiliser une astuce: l’exponentiation rapide.
puissance(M, k) = | I si k = 0
| puissance(M^2, k/2) si k est pair
| M * puissance(M^2, (k-1)/2) sinonOù I représente la matrice identité, avec seulement des 1 sur la diagonale. On calcule donc Mk, et on retourne la somme de la m-ème ligne, c’est à dire le nombre total de fois que fk passe par m. En utilisant la variable a comme accumulateur, on a donc:
n = $stdin.gets.to_i
f = $stdin.gets.strip.split.map(&:to_i)
k = $stdin.gets.to_i
def matrix(n)
Array.new(n) { |i| Array.new(n) { |j| yield(i,j) } }
end
def multiply(n, m, a)
matrix(n) do |i,j|
(0...n).inject(0) { |s, u| s + m[i][u] * a[u][j] } % 1000
end
end
m = matrix(n) { |i,j| (f[j] <= i && i < f[j+1]) ||
(f[j] > i && i >= f[j+1]) ? 1 : 0 }
a = matrix(n) { |i,j| i == j ? 1 : 0 }
while k > 0
a = multiply(n, m, a) if k % 2 != 0
m = multiply(n, m, m)
k /= 2
end
puts a[n/2].sum % 1000Solution 3 : Programmation dynamique
Juste une dernière pour le plaisir. Il y a une autre façon intelligente de calculer la puissance k-ème de M. En effet les coefficients de M sont tous 0 ou 1, donc la multiplication par M s’écrit comme une simple somme, pas besoin de produits. D’autre part, on a besoin que de la m-ème ligne de M, donc inutile de calculer les autres. Il se trouve qu’on peut calculer la m-ème ligne de Mk+1 avec uniquement la m-ème ligne de Mk
M^(k+1) [m, j] = somme sur u : M^k [m, u] * M[u, j]Il s’agit en quelque sorte d’une variante de la mémoïsation dans un cas un peu particulier: celui où la dépendance entre les différentes valeurs du tableau à calculer est facile à comprendre. On peut donc choisir un ordre dans lequel remplir le tableau de façon à ce que toutes les valeurs dont on a besoin pour remplir une case aient été calculées avant qu’on ait à calculer la case en question. Ici, on peut calculer M[k, i, j] par valeurs de k croissantes. Comme chaque puissance de M ne dépend que de la précédente, on a même pas besoin de les stocker toutes. Et enfin, comme on ne se sert que d’une ligne de M, on est pas obligé de stocker (ni même de calculer) les autres lignes. Cette technique porte le nom de programmation dynamique.
n = $stdin.gets.to_i
f = $stdin.gets.strip.split.map(&:to_i)
k = $stdin.gets.to_i
intersections = Array.new(n) { |u| (u == n/2) ? 1 : 0 }
k.times do
intersections = Array.new(n) do |j|
a, b = [f[j], f[j+1]].sort
intersections[a...b].sum
end
end
puts (intersections.sum % 1000)Si on est un adepte un peu plus expérimenté du Ruby, on peut même raccourcir ça encore un peu pour la beauté du geste, avec Array.reduce, mais ça devient tout de même un peu moins lisible.
n = $stdin.gets.to_i
f = $stdin.gets.strip.split.map(&:to_i)
k = $stdin.gets.to_i
puts ((1..k).reduce(Array.new(n) { |u| (u == n/2) ? 1 : 0 }) do |s,_|
Array.new(n) { |j| s[Range.new(*[f[j], f[j+1]].sort, true)].sum }
end.sum % 1000)Soit un total de 7 lignes de code pour le challenge supposé le plus difficile. Un peu frustrant quand on y pense, non ?
-
Fonction affine par morceaux sur Wikipédia ↩
-
Théorème des valeurs intermédiaires sur Wikipédia ↩
-
Si vous n’avez pas l’habitude de déterminer la complexité temporelle d’un algorithme, je vous invite à consulter l’article Complexité en temps sur Wikipédia pour quelques exemples, et le chapitre complexité du cours d’informatique de Jean-Pierre Becirspahic pour de plus amples explications. ↩
-
Problème 2-SAT sur Wikipédia, à ne pas confondre avec le problème nettement plus difficile 3-SAT, qui est lui NP-complet. ↩
-
Pour une preuve détaillée, voir cp-algorithms.com (en anglais). ↩
